Where do data come from? What are the main types of data?
There are five main sources (and types) of data:
- Surveys catalogue data about people or places. They can be large (the U.S. Census) or small (a survey of voters in a ZIP code). They can be one-time or ongoing (longitudinal). The Detroit Residential Parcel Survey, for example, catalogued every residential property in the city.
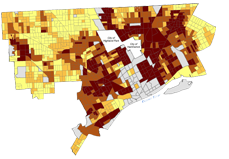
- Qualitative data, collected through methods like in-depth interviews or focus groups, include the kinds of the information that are harder to capture with numbers, such as residents' perceptions of their neighborhood, or the historical and political factors shaping local conditions.
- Administrative data are collected as part of a government agency's daily operations. Useful for record keeping at federal, state, and local levels, these data – which include data on education, health, income, property transactions, and a host of other socio-economic factors — are also valuable to researchers and practitioners.
- Integrated data are data from multiple agencies or sources that are linked together, like this that links education, juvenile justice, and health and services data to identify those at high risk for absenteeism.
- Big Data are data with very high volume and variety that traditional number crunching methods can't handle. Data from traffic sensors that every 20 seconds capture cars passing at hundreds of locations around a region is an example. (The definition is up for debate.)
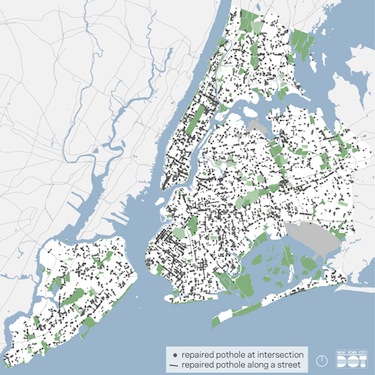
Why should program administrators and staff use data?
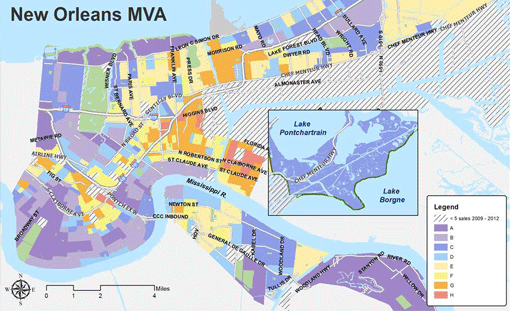
How does using data empower communities?
Aren't data used as a "gotcha" to point to programmatic failures or problems?
How can data support policymakers?
What role can community members play in data and research?
How can data promote collaboration and break down silos?
What is better: rigor in measures or usability?
How do organizations get started?