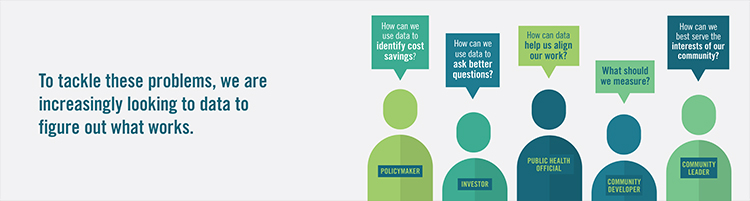
Building neighborhood data to inform policy: A Q&A with Kathryn Pettit, director of the National Neighborhood Indicators Partnership (NNIP)
In this Q&A, Stuart Butler talks with Kathryn Pettit, director of the National Neighborhood Indicators Partnership (NNIP). The NNIP is a peer-learning network of organizations in 30 cities that helps community organizations, foundations, and local governments use data to help shape policy.
Learn More