Promoting Economic Participation through Regional Equity
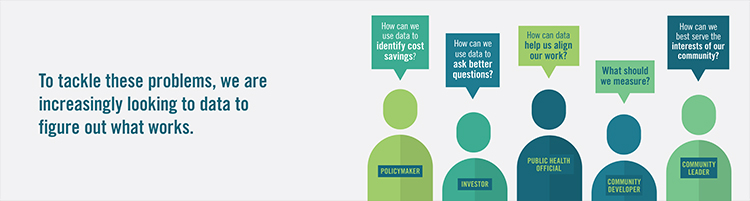
What is regional equity? In the context of the San Francisco Fed’s work, regional equity means ensuring that all individuals, regardless of race, ethnicity, geographic location, or other demographic factors, can fully contribute their talents and skills to the economy and benefit from it. The San Francisco Fed studies the underlying conditions that influence people’s access to opportunities as part of its mission to promote a healthy, inclusive, and sustainable economy and support the nation’s financial and payment systems. Where people live within a region—whether it's the Bay Area, the Inland Empire, the Seattle metro area, or the Salt Lake...
Learn More